Database transaction handling in C++ systems
Architectural approach of a way to handle transactions in C++ systems. The approach aims to be as decoupled and non-invasive as possible.

Concurrency (either by multithreading or asynchonicity) and database usage are present in every software system.
Transactions are the mechanism given by relational databases to provide ACID properties to the execution of multiple statements.
In order to use them, most database systems expect transactions to take place in a single database connection by using explicit boundaries.
This means that in order to perform X database actions as a single logical operation the system needs to: get a connection to the database, start a transaction on the connection, execute the actions over that connection and finish the connection's ongoing transaction.
The application can tell whether to finish the transaction by applying the changes or rollback all the performed changes and leave the DB in the exact same form as it was before starting the transaction.
Also, the DBMS might forcefully finish abort the transaction due to conflicts generated by other transactions.
In most C++ systems I have worked on I have found that transactions are not handled in a nice way from the architectural point of view.
I can basically classify the transaction management and handling in one of two options:
- Database layer abstracted but not allowing transactions. This situation is represented by the architecture where there are multiple classes acting as repositories which interface with the database. But the abstraction handles the acquisition and release of the DB connection, thus not allowing to have a transaction that can cover multiple methods across one or more repositories. To give an example, there is a repository for the
Accountobject with two methods:saveandgetById. Each of the methods acquires a connection performs the DB operation and then releases the connection.
As each method acquires its own connection, there is no way to have a transaction across the two methods. - Database implementation polluting business logic. In this case, we have the business logic acquiring a connection and starting a transaction and passing the DB connection to other methods so that they can pass it to the DB layer.
Now, you are able to use transactions in the system but the business logic needs to know the underlying layer in order to start the transaction and also all the functions that might be called need to take the DB connection object as an argument.
None of the aforementioned solutions is a good one. We would like to have the abstraction of the first scenario but with the possibility that the business logic can declare that a certain set of actions should be done within a transaction.
Solution Approach
Architecture
Let's see how we can tackle this issue in a nice way.
The following UML diagram shows an architectural approach to the transaction handling program that decouples all the components as much as possible.
The decoupling is important because we want to be able to mock most of the things in order to successfully test our code.
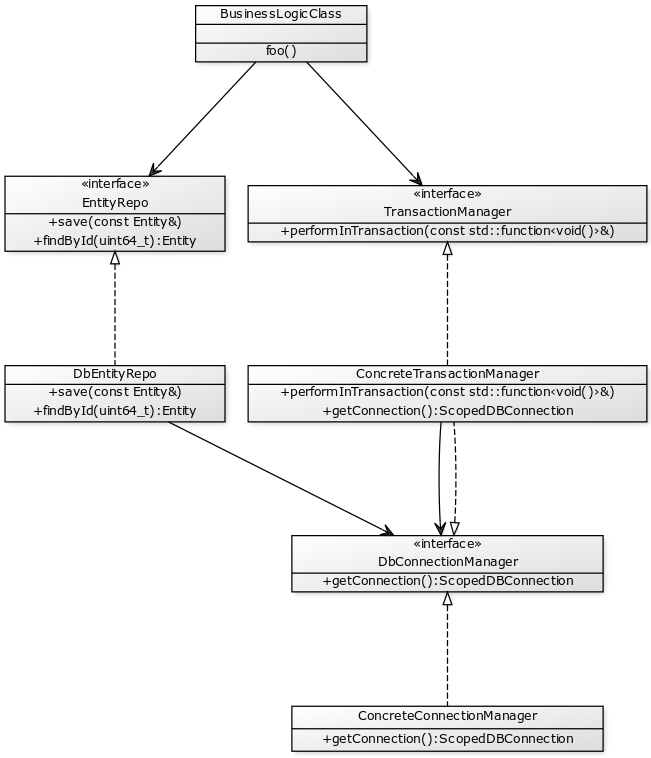
Business logic
If the business logic requires actions to be run under the context of a single transaction, then it will need to know about the transaction manager.
As the management of transactions is very specific to each implementation, what the business logic actually knows and interacts with is an object that implements the TransactionManager interface.
This interface will provide an easy way of executing actions within a single transaction context.
In order to interact with the database layer, the business logic will still need to have knowledge and interact with the model's repositories. Of course, this is done through an interface and not a concrete type.
Entity repositories
The repositories don't change at all.
They use the same interface to retrieve the connections they need to execute the queries.
The difference will be in the setup, instead of using the DbConnectionManagerdirectly, they will use the ConcreteTransactionManager which also implements the DbConnectionManager interface.
This means that the repositories don't actually care whether a transaction is happening or not.
Transaction Manager
The transaction manager is the key piece in this design.
Its purpose is to provide a clear way for the business logic to perform a sequence of actions in the same transaction, while hiding the details of how that transaction is handled.
By using the transaction manager, the business logic doesn't need to know the underlying implementation of how the persistence layer initiates or closes the transaction.
It also removes the responsibility from the business layer to keep moving the transaction state from call to call.
Thus, allowing a component of the business logic that requires transactional behavior to call another who doesn't but still get transactional results if the latter one fails.
In the diagram above, I assumed the scenario where the transaction is handled through the DB connection, which might not be the case.
The way in which the transaction manager and repositories interact will depend entirely on the technicality of how the transaction mechanism needs to be implemented.
Behavior and usage
From the business logic's point of view what we want to achieve is that the usage is somewhat like this:
void BusinessLogic::foo()
{
transactionManager.performInTransaction([&]() {
Entity a = entityRepo.getById(123);
if (a.x > 20) {
a.x -= 20;
}
entityRepo.save(a);
});
}
Everything that is executed inside the lambda given to the transaction manager, should be done in the context of a single transaction.
When the lambda returns, the transaction gets committed.
That way would be fine if transactions cannot fail, but that is not the case.
The easiest way for the TransactionManager to communicate the failure of a transaction is through an exception.
In that case we should enclose the call to the transaction manager in a try-catch clause like this:
void BusinessLogic::foo()
{
try {
transactionManager.performInTransaction([&]() {
Entity a = entityRepo.getById(123);
if (a.x > 20) {
a.x -= 20;
}
entityRepo.save(a);
});
}
catch (const TransactionAborted&) {}
}
There is one more thing we need to add to make it more complete at a basic level.
The business logic needs to be able to trigger a transaction rollback on its own.
For that we can also use C++ exception mechanism, the lambda can throw an AbortTransaction which will make the transaction to be rolled back silently.
As it was the user who asked for the rollback, the performInTransaction call should finish normally and not through an exception as was the case for the failed transaction.
Nested transactions
The purpose of this blog-post is not to write a full-fledged transaction manager, but to show an architectural solution that is decoupled, versatile and easily expandable.
For the sake of simplicity I am going to assume that if transaction nesting occurs the nested transaction is irrelevant.
That is, everything will be done in the context of the outer transaction.
PoC Implementation: a transaction manager for SQLite
As a proof of concept of of this architecture, I am going to write a simple transaction manager for SQLite and write a couple of test cases to show the behavior.
The code is in the following gist: TransactionManagerArchitecturePoC.cpp.
Let's disassemble the code into the different components.
ScopedDbConnection and ConcreteConnectionManager
In order to make things simple, the ScopedDbConnection is just a std::unique_ptr that takes a std::function<void(sqlite3*)> as its deleter.
Doing this, allows us to return a ScopedDbConnection from the TransactionManager that when it gets destructed, it either actually closes the connection or does nothing if the connection belongs to an on-going transaction.
The ConcreteTransactionManager::getConnection() method, simply creates and returns a ScopedDbConnection to the DB we are using.
When this scoped connection gets destructed, the underlying connection gets closed.
Transaction manager
There are two important components in the transaction manager: the protocol for transactions and its internal state to give support to the transaction protocol.
The state is composed by one internal data type (TransactionInfo) and a std::map from threads to TransactionInfo instances.
A std::mutex also forms part of the transaction manager's state and is used to synchronize access to the map.
The TransactionInfo is a structure that holds a ScopedDbConnection and a counter.
This counter is used to keep track of transaction nesting.
The transaction handling protocol is the meat of the class, this is what actually handles when a transaction gets initialized and when it gets committed or aborted.
Let's take a look at that code:
void ConcreteTransactionManager::performInTransaction(const std::function<void()>& f)
{
auto threadId = std::this_thread::get_id();
TransactionInfo& transactionInfo = setupTransaction(threadId);
try {
f();
}
catch (AbortTransaction&) {
if (--transactionInfo.count > 0) {
throw;
}
abortTransaction(transactionInfo);
return;
}
catch (...) {
if (--transactionInfo.count > 0) {
throw;
}
abortTransaction(transactionInfo);
throw;
}
if (--transactionInfo.count > 0) {
return;
}
commitTransaction(transactionInfo);
}
The protocol is really simple: when starting into a performInTransaction block, we setup the transaction which results in a TransactionInfo object reference.
Then we execute the given function and when that function exits, we reduce the count on the transaction information object.
When the count reaches 0, depending on how we reached the count, the transactions gets committed or aborted.
In case the transaction finished by an exception different than AbortTransaction, the exception is re-thrown.
commitTransaction and abortTransaction are really simple functions that just execute a statement using the connection from the transaction.
They also remove the transaction from the on-going transaction map.
The setupTransaction is also really simple: it checks whether there is an on-going transaction for the given threadId, if there is then it just increments its count and returns.
If there's not it initializes a new TransactionInfo, places it in the map and executes the statement to start a transaction.
The other important function in this class is getConnection.
This needs to handle two cases: (a) if something is executed outside the context of a transaction, the returned connection needs to destroy itself when going out of scope; and (b) if a connection is requested within the context of a transaction, the ScopedDbConnection returned must not close the inner connection when going out of scope.
The way I decided to handle the latter is to return a new ScopedDbConnection containing the sqlite3 connection of the transaction but with an innocuous deleter.
This way for the client is totally transparent whether the connection comes from a transaction context or not.
ScopedDbConnection ConcreteTransactionManager::getConnection()
{
auto threadId = std::this_thread::get_id();
std::lock_guard<std::mutex> _(_currentTransactionsMutex);
auto it = _currentTransactions.find(threadId);
if (it == _currentTransactions.end()) {
return _connectionManager.getConnection();
}
return ScopedDbConnection(it->second.dbConnection.get(), [](sqlite3* c) {});
}
The developed transaction manager has the following properties:
- Transactions are per thread. This means that the transaction is associated to the thread who started it.
Only the actions performed by that thread included in the transaction. - Transactions cannot be shared. This derives from the former item and means that one thread cannot give its current transaction to other threads.
So, if thread A opens a transaction and launches thread B, the actions that thread B performs are not covered by the transaction initiated by thread A and there is no way to make that happen. - There are no nested transactions. If while in the context of a transaction a new call to
executeInTransactionis made, this second call doesn't have any practical effect.
A call to abort aborts the already on-going transaction and a successful exit from the inner transaction doesn't trigger a commit of the outer transaction.
Conclusion
Advantages of the given design
One of the most important advantages this design has is that it is so decoupled that mocking it is really easy to do.
This helps testing the code that uses it with minimal effort and no dependencies.
It is also really easy to use and transparent that it is really non-intrusive to the code that uses it.
And only the code that wants to use transaction capabilities requires knowledge of it.
The rest of the code that needs to interact with it in order to provide the transaction functionalities (i.e the repos or whoever uses the DB) don't know about transactions.
This gets masked by the TransactionManager providing the ConnectionManager interface.
Also all the transactional functionality, is encapsulated by the TransactionManager.
This makes it easier to test implementations in isolation without requiring other components to know any logic about transactions.
What can be improved?
The PoC is really simple and there are many edge cases that it doesn't take into account.
When implementing a production solution, one has to be aware that the repositories can fail due to transaction problems and probably mask those as a TransactionAborted.
For my PoC, I decided to use abstract classes and virtual functions to provide polymorphism, but this can be implemented using templates.
It is also arguable that the ScopedDbConnection returned carries no guarantees that it is not going to be retained by the callee.
A different approach needs to be taken to guarantee that: maybe the connection manager can have a method executeOnConnection(std::function<void(const ScopedDbConnection&)>).